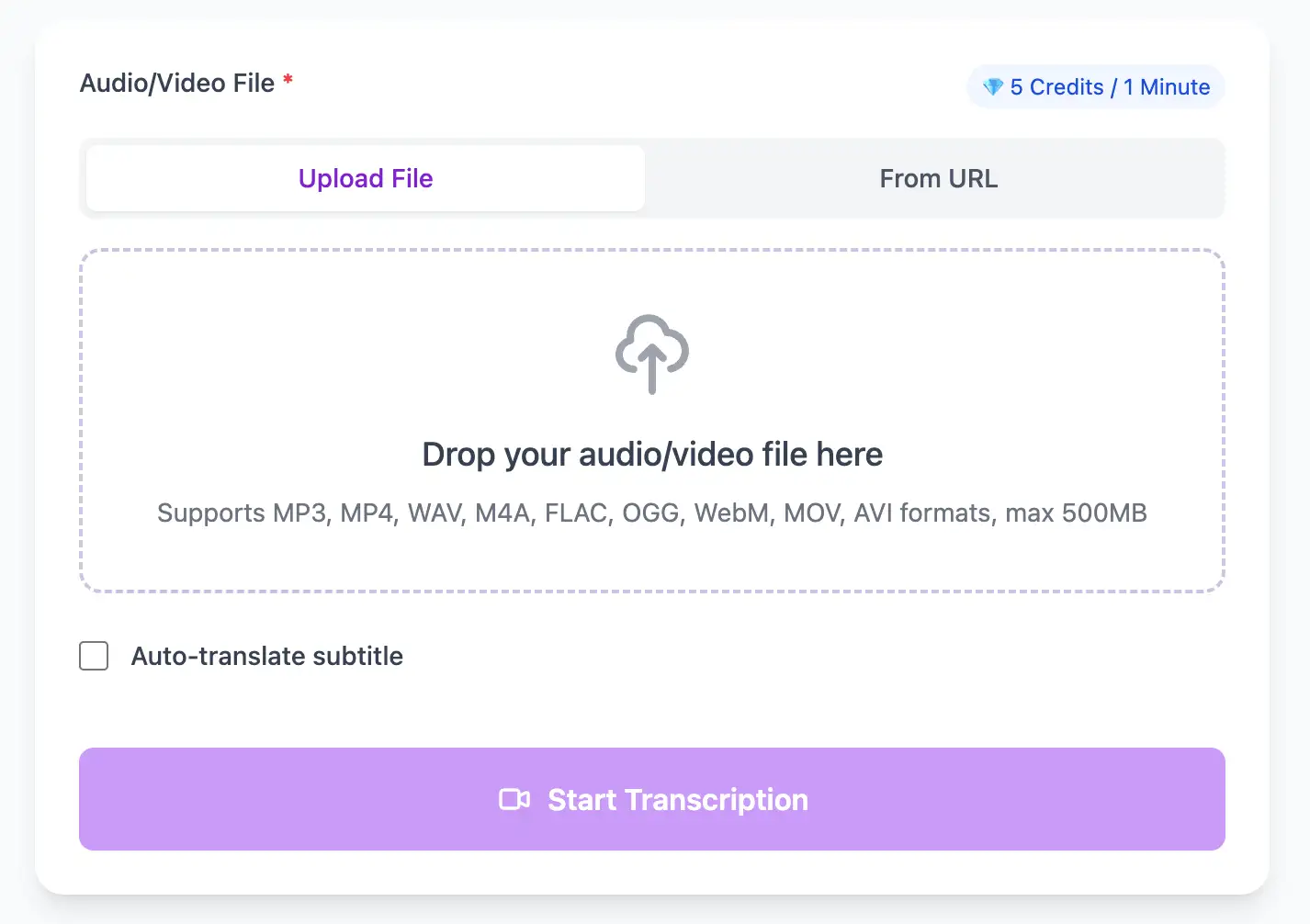
1
Prepare and upload your speech recording
For best results, use clear audio with minimal background noise. Upload any audio or video file, or record directly in your browser. Our AI auto-detects the language.